|
Animesh Gupta अनिमेष गुप्ता I am a PhD student at the University of Central Florida, supervised by Dr. Mubarak Shah. My research focuses on Multimodal Learning across images, videos, and 3D data, with a particular interest in developing models for Retrieval tasks. Prior to this, I worked as a Machine Learning Engineer Intern at MVisionAI, where I contributed to medical image registration for radiotherapy planning. I received my Bachelor's degree in Electronics and Computer Science from Thapar University, India. I also completed research internships at UiT - The Arctic University of Norway, where I worked on coreset-based data selection for efficient model training, and at the SketchX Lab, University of Surrey, contributing to sketch-based visual understanding. 🔍 Actively looking for summer internship opportunities | 🤝 Open to research collaborations |

|
What's New 📣
Research Interests 🧭I am broadly interested in retrieval tasks using multimodal models that integrate vision, language, and 3D data, with emphasis on modeling efficiency and fine-grained temporal reasoning. |
Publications 📑
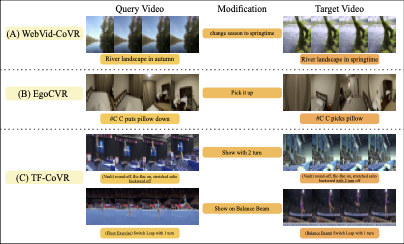
From Play to Replay: Composed Video Retrieval for Temporally Fine-Grained Videos
@misc{gupta2025playreplaycomposedvideo,
title={From Play to Replay: Composed Video Retrieval for Temporally Fine-Grained Videos},
author={Animesh Gupta and Jay Parmar and Ishan Rajendrakumar Dave and Mubarak Shah},
year={2025},
eprint={2506.05274},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05274},
}
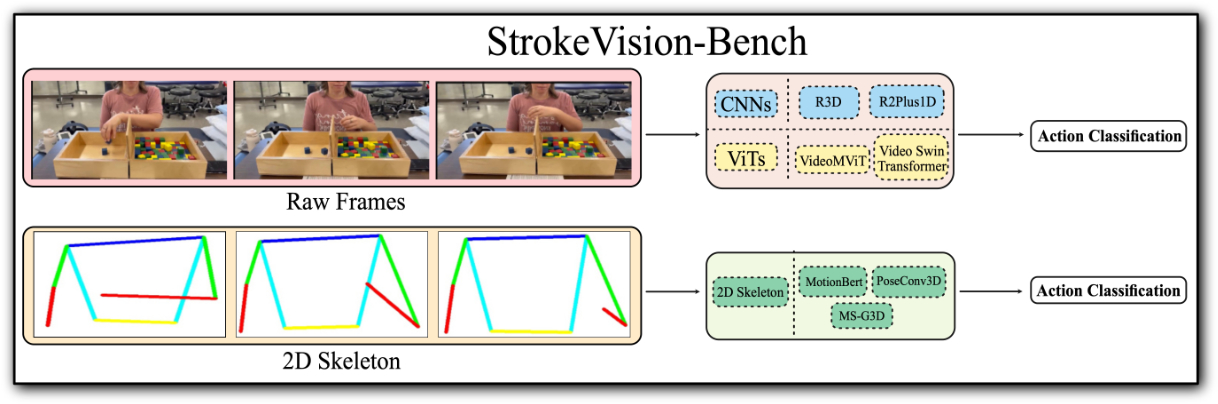
STROKEVISION-BENCH: A Multimodal Video And 2D Pose Benchmark For Tracking Stroke Recovery
@inproceedings{robinson2025strokevision,
title={Strokevision-Bench: A Multimodal Video and 2D Pose Benchmark for Tracking Stroke Recovery},
author={Robinson, David and Gupta, Animesh and Qureshi, Rizwan and Fu, Qiushi and Shah, Mubarak},
booktitle={2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP)},
pages={1--6},
year={2025},
organization={IEEE}
}
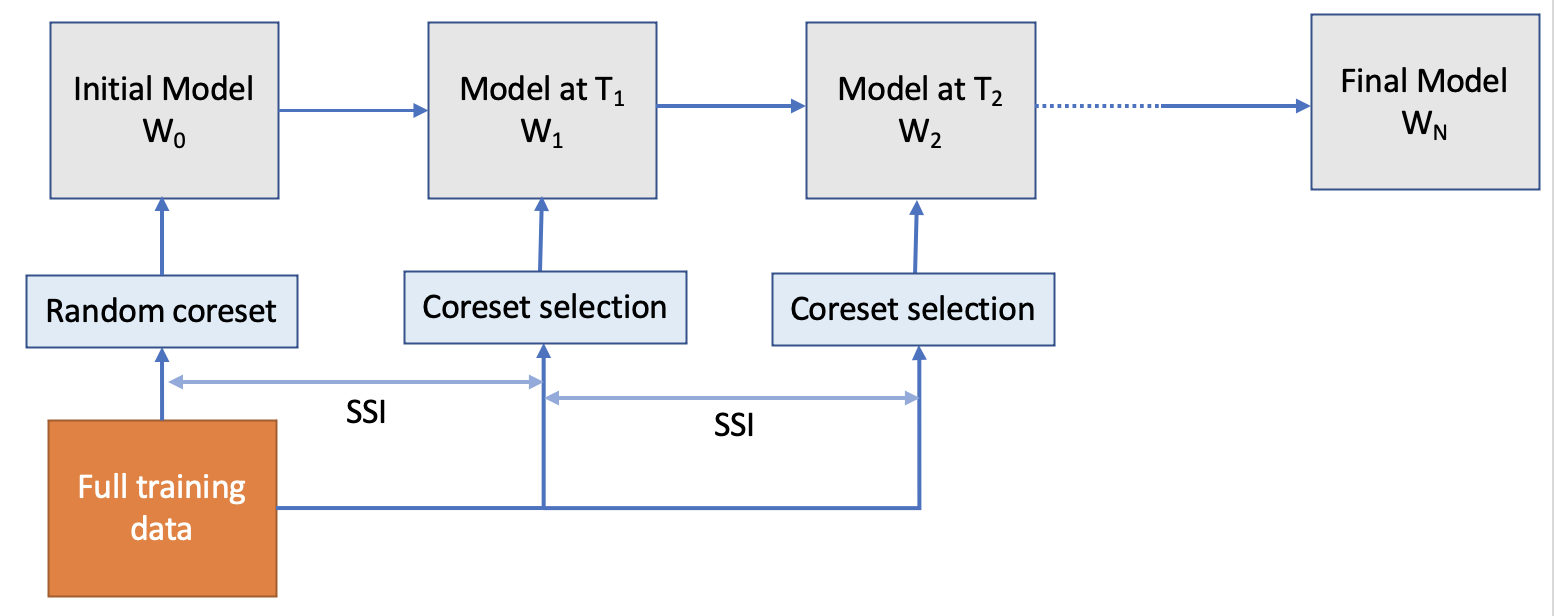
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
@article{gupta2023data,
title={Data-Efficient Training of CNNs and Transformers with Coresets},
author={Gupta, Animesh and Hassan, Irtiza and Prasad, Dilip K and Gupta, Deepak K},
year={2023}
}
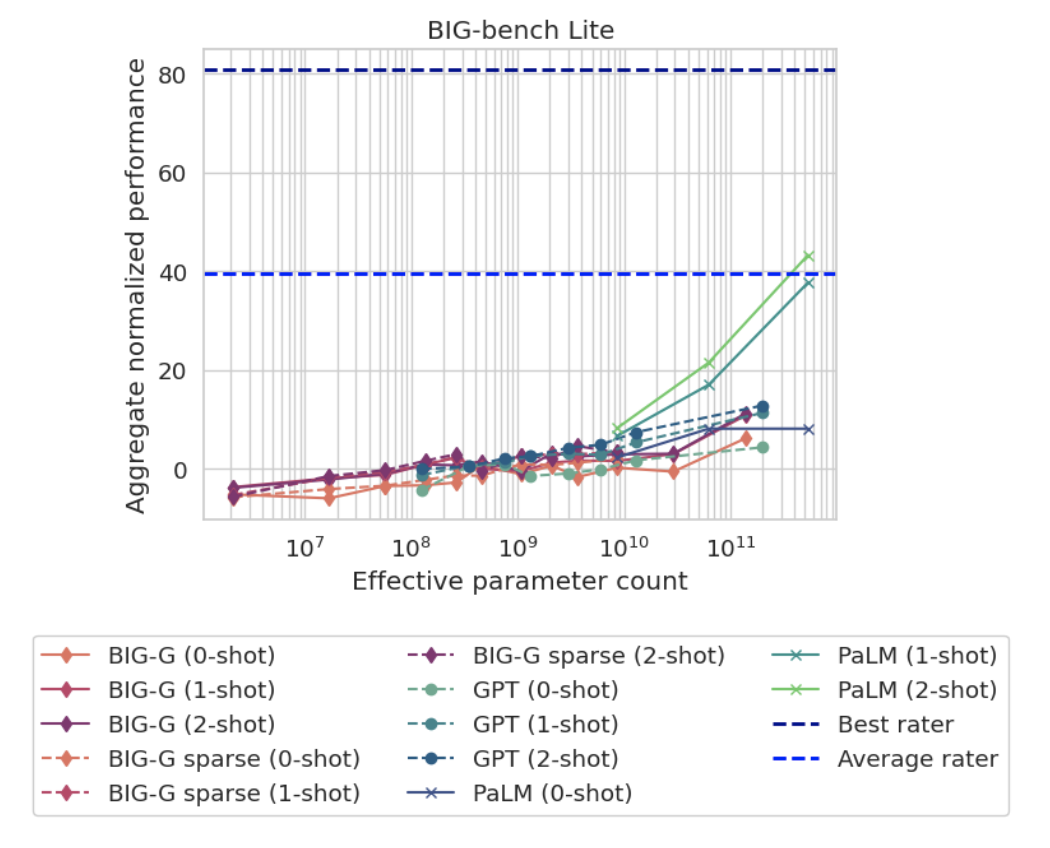
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
@article{srivastava2022beyond,
title={Beyond the imitation game: Quantifying and extrapolating the capabilities of language models},
author={Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adri{\`a} and others},
journal={arXiv preprint arXiv:2206.04615},
year={2022}
}
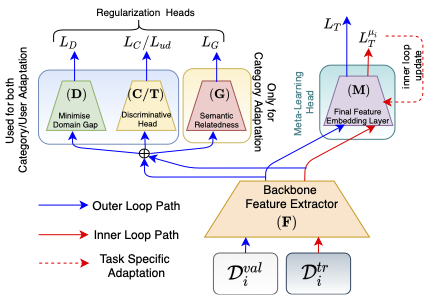
Adaptive Fine-Grained Sketch-Based Image Retrieval
@inproceedings{bhunia2022adaptive,
title={Adaptive fine-grained sketch-based image retrieval},
author={Bhunia, Ayan Kumar and Sain, Aneeshan and Shah, Parth Hiren and Gupta, Animesh and Chowdhury, Pinaki Nath and Xiang, Tao and Song, Yi-Zhe},
booktitle={European Conference on Computer Vision},
pages={163--181},
year={2022},
organization={Springer}
}
Research Experience 📚

- Worked on radiotherapy planning using multi-modal image registration (CT and MRI).
- Built an efficient library supporting multiple datasets and algorithms.
- Adapted RWCNet and Transmorph for OASIS and NLST datasets; established AbdomenCTCT baselines.

- Created a benchmarking setup for coreset selection on CNNs and Transformers.
- Showed class-complexity-driven sampling outperforms uniform sampling.
- Work led to a research publication under review.

- Worked on real-time lane detection and vision transformers for DRIVE-Perceptron.
- Focused on optimizing inference and improving real-world performance.

- Worked on fine-grained and category-level sketch-based image retrieval.
- Co-authored ECCV 2022 paper on few-shot FG-SBIR adaptation across categories and styles.


- Worked on road segmentation for autonomous driving in Indian traffic scenarios.
- Trained FCHarDNet on a 10k-image dataset annotated with 34 semantic classes.
|
I borrowed this website layout from here! |